Request throttling
TLDR; Request throttling* is the technique of selectively refusing requests to protect a service from being overwhelmed by demand.
- a.k.a rate limiting/API throttling/server-side throttling
Service overload
There are 2 core ideas to consider when thinking about a service's ability to serve requests:
- A service must do work for every request made against it A website must render a webpage; an API must fetch data from a database, then filter and transform it before sending it back. This work requires resources: the CPU works harder, more data is accessed from data-storage devices, etc. This means that there amount of requests that a service can serve. When a service reaches its limit, it can behave unexpectedly (which is almost always a bad thing) or crash altogether.
- A service has no control over where requests come from An internet service is open to anyone that wants to call against them, at any time. So it is possible - and common - for a large amount of requests to hit a service without warning.
A spike in demand against the service will often cause a spike in the resource usage/load on the service. These spikes can occur at any time and - if the service is not prepared or protected - the resulting "load spike" on the service can overwhelm and take down the service.
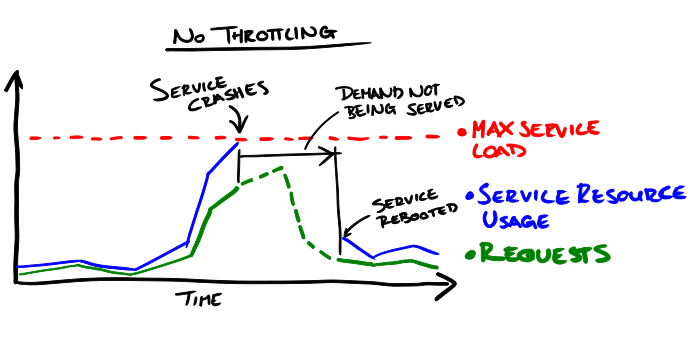
Selectively shedding load
In practice, events which cause load spikes often have a hot-spot e.g. a load spike event was caused when users were linked to a page from a popular Reddit post. Hotspots allow us to classify problematic load: we can distinguish traffic going to the hotspot from traffic going to other pages on the website. Once classified, we can limit the amount of requests we serve for a particular class, hopefully preventing the service from being overloaded.
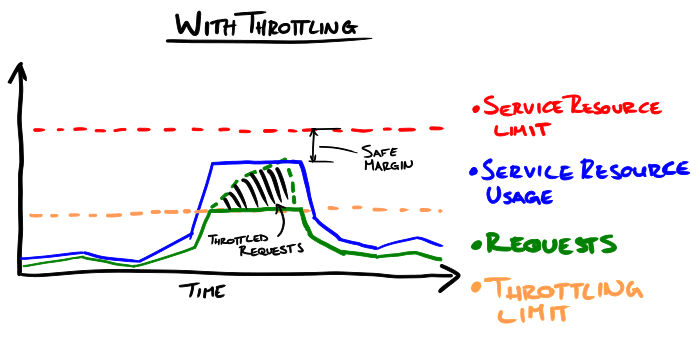
So, what do we need to do to throttle? We need 4 things:
- An axis - This is another name for a class/category of requests. We'll need an algorithm or mechanism for categorizing requests. Example axes are the a user's account ID; the type of request; the specific API method which the request is calling against; a resource which the request is attempting to access.
- An aggregation - we need some way of turning requests in an axis into a number that we can set a limit on. We'll need an algorithm for this aggregation. Example aggregations are the number of requests; the amount of results that the requests would return; the total amount of bits that the requests would send back.
- A period over which to perform one aggregation.
- A limit/threshold to set on the aggregation.
Example: We decide to throttle calls when user12314 (axis) downloads more than 750MB of data (aggregation and limit) in 10 seconds (period).
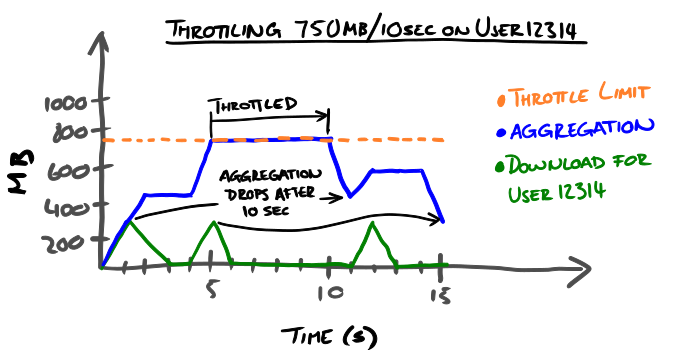
Limitations
Throttling looses some effectiveness when the axes are badly chosen or if demand hits every axis equally or at random. In these cases, the combination of requests being served across axes could still cause more load than the service can handle.
From the other perspective
We've looked at throttling from the service's side. Let's take a quick look at it from the user's side.
How do I know I've been throttled? The standard response for requests which are denied via throttling is HTTP 429, though some services have also been known to return HTTP 503.
What do I do with a throttled response? When receiving a throttling exception, the best thing is to wait - to give the service some time to recover - then retry the same request. This is called backoff and retry. There are multiple ways to do this, but a good general-purpose algorithm is exponential backoff and retry.
Read on
- Article: Go full throttle: The essentials of throttling in your application architecture - A more in-depth introduction to throttling.
- Video: Approaches for application request throttling - Conference talk iteratively implementing a throttling solution.
- Video: Cloud Patterns for Resiliency (Circuit Breakers and Throttling) - Conference talk explaining throttling from cloud-services.